Research
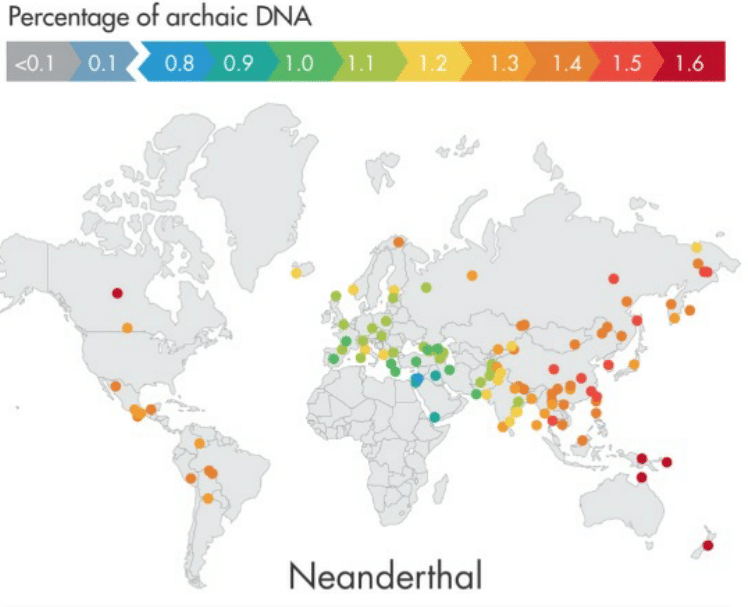
Population genetic inference
We are interested in understanding how evolutionary forces such as population history, selection and mutation impact genetic variation. We aim to answer these questions by analyzing DNA sequences from ancient as well present-day humans. See Sankararaman et al. 2014.
Understanding the links between genetics and complex traits
We are interested in identifying genes underlying diseases as well as complex traits (association), in understanding the mapping from genetics to traits (genetic architecture), as well as in predicting traits from genetic data. See Johnson et al. 2018
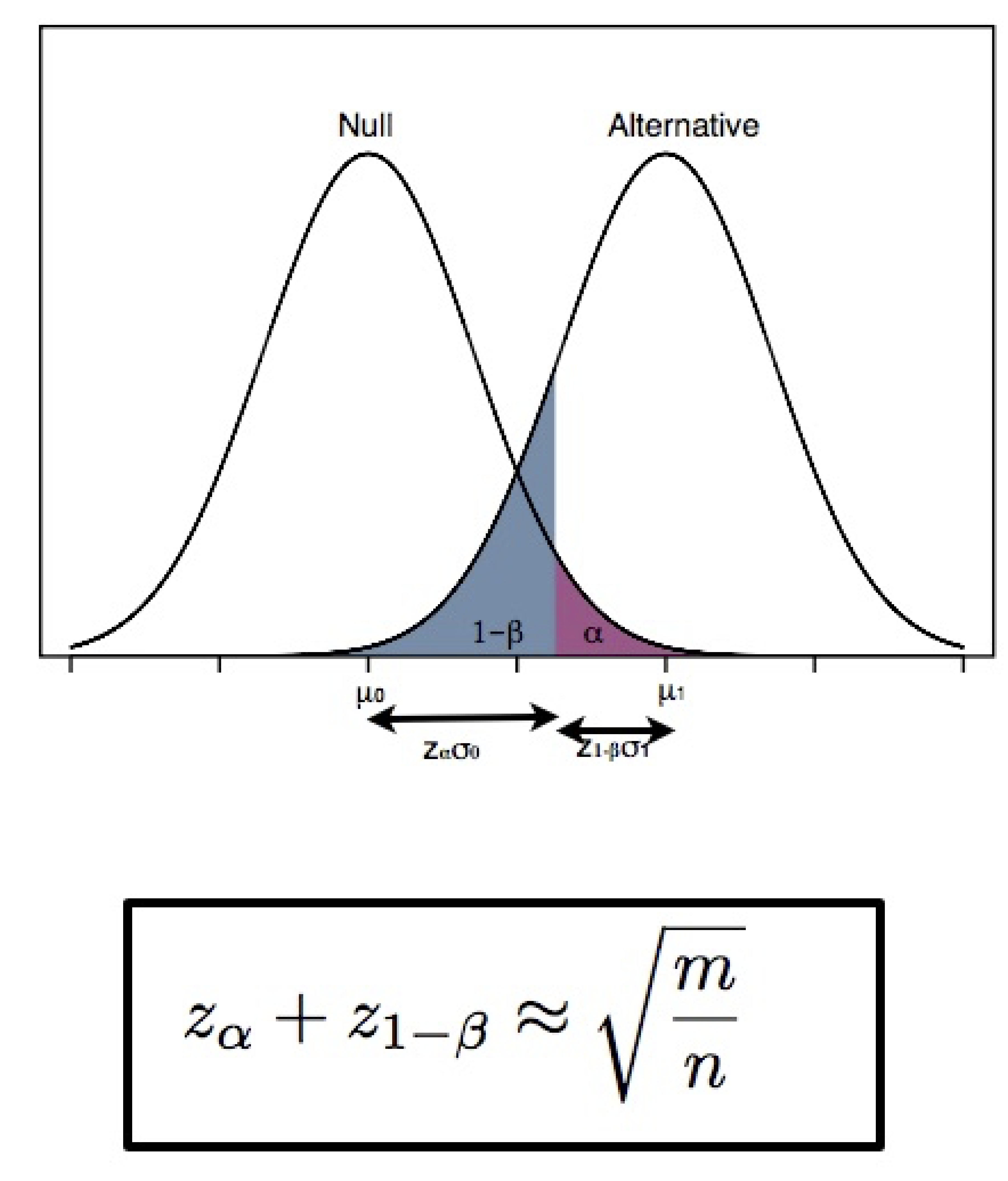
Genomic privacy
A major challenge in analyzing genomic and biomedical data arises from concerns about the privacy of participants. We are interested in understanding how privacy might be breached as well as how we might be able to mitigate such risks. See Sankararaman et al. 2009.
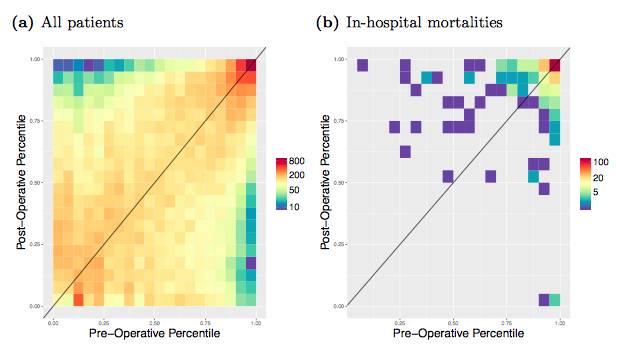
Machine learning for clinical data
We are part of an interdisciplinary team that is building machine learning methods to predict clinically relevant outcomes using electronic medical records from the UCLA Hospitals. See Hill, Brown et al. BiorXiv
Machine learning for large-scale genomics
We are interested in building rich statistical models that can effectively harness the power of datasets such as the UKBiobank that contain genotypes from half a million individuals. A key question is the design of inference algorithms that can scale to these massive datasets while retaining favorable statistical properties. See Wu et al. Bioinformatics 2018.